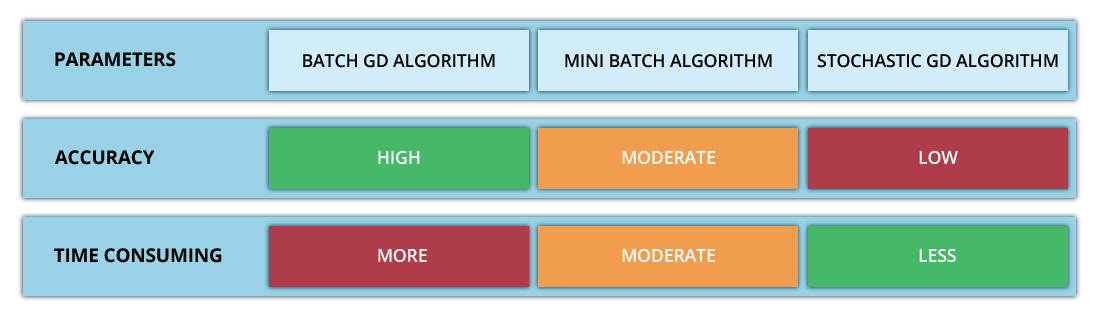
In this article, we learned about the basics of gradient descent algorithm and its types. These optimization algorithms are being widely used in neural networks these days. Hence, it's important to learn. The image below shows a quick comparison in all 3 types of gradient descent algorithms:
Subscribe to The HackerEarth Blog
Get expert tips, hacks, and how-tos from the world of tech recruiting to stay on top of your hiring!
Thank you for subscribing!
We're so pumped you're here! Welcome to the most amazing bunch that we are, the HackerEarth community. Happy reading!
Revolutionizing Mobile Talent Hiring: The HackerEarth AdvantageThe demand for mobile applications is exploding, but finding and verifying developers with proven, real-world skills is more difficult than ever. Traditional assessment methods often fall short, failing to replicate the complexities of modern mobile development.Introducing a New Era in Mobile AssessmentAt HackerEarth, we're...
Revolutionizing Mobile Talent Hiring: The HackerEarth Advantage
The demand for mobile applications is exploding, but finding and verifying developers with proven, real-world skills is more difficult than ever. Traditional assessment methods often fall short, failing to replicate the complexities of modern mobile development.
Introducing a New Era in Mobile Assessment
At HackerEarth, we're closing this critical gap with two groundbreaking features, seamlessly integrated into our Full Stack IDE:
Now, assess mobile developers in their true native environment. Our enhanced Full Stack questions now offer full support for both Java and Kotlin, the core languages powering the Android ecosystem. This allows you to evaluate candidates on authentic, real-world app development skills, moving beyond theoretical knowledge to practical application.
Say goodbye to setup drama and tool-switching. Candidates can now build, test, and debug Android and React Native applications directly within the browser-based IDE. This seamless, in-browser experience provides a true-to-life evaluation, saving valuable time for both candidates and your hiring team.
Assess the Skills That Truly Matter
With native Android support, your assessments can now delve into a candidate's ability to write clean, efficient, and functional code in the languages professional developers use daily. Kotlin's rapid adoption makes proficiency in it a key indicator of a forward-thinking candidate ready for modern mobile development.
This chart illustrates the importance of assessing proficiency in both modern (Kotlin) and established (Java) codebases.
Streamlining Your Assessment Workflow
The integrated mobile emulator fundamentally transforms the assessment process. By eliminating the friction of fragmented toolchains and complex local setups, we enable a faster, more effective evaluation and a superior candidate experience.
Visualize the stark difference: Our streamlined workflow removes technical hurdles, allowing candidates to focus purely on demonstrating their coding and problem-solving abilities.
Quantifiable Impact on Hiring Success
A seamless and authentic assessment environment isn't just a convenience, it's a powerful catalyst for efficiency and better hiring outcomes. By removing technical barriers, candidates can focus entirely on demonstrating their skills, leading to faster submissions and higher-quality signals for your recruiters and hiring managers.
A Better Experience for Everyone
Our new features are meticulously designed to benefit the entire hiring ecosystem:
For Recruiters & Hiring Managers:
Accurately assess real-world development skills.
Gain deeper insights into candidate proficiency.
Hire with greater confidence and speed.
Reduce candidate drop-off from technical friction.
For Candidates:
Enjoy a seamless, efficient assessment experience.
No need to switch between different tools or manage complex setups.
Focus purely on showcasing skills, not environment configurations.
Work in a powerful, professional-grade IDE.
Unlock a New Era of Mobile Talent Assessment
Stop guessing and start hiring the best mobile developers with confidence. Explore how HackerEarth can transform your tech recruiting.
A New Era of CodeVibe coding is a new method of using natural language prompts and AI tools to generate code. I have seen firsthand that this change makes software more accessible to everyone. In the past, being able to produce functional code was a strong advantage for developers. Today,...
A New Era of Code
Vibe coding is a new method of using natural language prompts and AI tools to generate code. I have seen firsthand that this change makes software more accessible to everyone. In the past, being able to produce functional code was a strong advantage for developers. Today, when code is produced quickly through AI, the true value lies in designing, refining, and optimizing systems. Our role now goes beyond writing code; we must also ensure that our systems remain efficient and reliable.
From Machine Language to Natural Language
I recall the early days when every line of code was written manually. We progressed from machine language to high-level programming, and now we are beginning to interact with our tools using natural language. This development does not only increase speed but also changes how we approach problem solving. Product managers can now create working demos in hours instead of weeks, and founders have a clearer way of pitching their ideas with functional prototypes. It is important for us to rethink our role as developers and focus on architecture and system design rather than simply on typing c
The Promise and the Pitfalls
I have experienced both sides of vibe coding. In cases where the goal was to build a quick prototype or a simple internal tool, AI-generated code provided impressive results. Teams have been able to test new ideas and validate concepts much faster. However, when it comes to more complex systems that require careful planning and attention to detail, the output from AI can be problematic. I have seen situations where AI produces large volumes of code that become difficult to manage without significant human intervention.
AI-powered coding tools like GitHub Copilot and AWS’s Q Developer have demonstrated significant productivity gains. For instance, at the National Australia Bank, it’s reported that half of the production code is generated by Q Developer, allowing developers to focus on higher-level problem-solving . Similarly, platforms like Lovable enable non-coders to build viable tech businesses using natural language prompts, contributing to a shift where AI-generated code reduces the need for large engineering teams. However, there are challenges. AI-generated code can sometimes be verbose or lack the architectural discipline required for complex systems. While AI can rapidly produce prototypes or simple utilities, building large-scale systems still necessitates experienced engineers to refine and optimize the code.
The Economic Impact
The democratization of code generation is altering the economic landscape of software development. As AI tools become more prevalent, the value of average coding skills may diminish, potentially affecting salaries for entry-level positions. Conversely, developers who excel in system design, architecture, and optimization are likely to see increased demand and compensation. Seizing the Opportunity
Vibe coding is most beneficial in areas such as rapid prototyping and building simple applications or internal tools. It frees up valuable time that we can then invest in higher-level tasks such as system architecture, security, and user experience. When used in the right context, AI becomes a helpful partner that accelerates the development process without replacing the need for skilled engineers.
This is revolutionizing our craft, much like the shift from machine language to assembly to high-level languages did in the past. AI can churn out code at lightning speed, but remember, “Any fool can write code that a computer can understand. Good programmers write code that humans can understand.” Use AI for rapid prototyping, but it’s your expertise that transforms raw output into robust, scalable software. By honing our skills in design and architecture, we ensure our work remains impactful and enduring. Let’s continue to learn, adapt, and build software that stands the test of time.
Ready to streamline your recruitment process? Get a free demo to explore cutting-edge solutions and resources for your hiring needs.
What is Systems Design?Systems Design is an all encompassing term which encapsulates both frontend and backend components harmonized to define the overall architecture of a product.Designing robust and scalable systems requires a deep understanding of application, architecture and their underlying components like networks, data, interfaces and modules.Systems Design, in its...
What is Systems Design?
Systems Design is an all encompassing term which encapsulates both frontend and backend components harmonized to define the overall architecture of a product.
Designing robust and scalable systems requires a deep understanding of application, architecture and their underlying components like networks, data, interfaces and modules.
Systems Design, in its essence, is a blueprint of how software and applications should work to meet specific goals. The multi-dimensional nature of this discipline makes it open-ended – as there is no single one-size-fits-all solution to a system design problem.
What is a System Design Interview?
Conducting a System Design interview requires recruiters to take an unconventional approach and look beyond right or wrong answers. Recruiters should aim for evaluating a candidate’s ‘systemic thinking’ skills across three key aspects:
How they navigate technical complexity and navigate uncertainty How they meet expectations of scale, security and speed How they focus on the bigger picture without losing sight of details
This assessment of the end-to-end thought process and a holistic approach to problem-solving is what the interview should focus on.
What are some common topics for a System Design Interview
System design interview questions are free-form and exploratory in nature where there is no right or best answer to a specific problem statement. Here are some common questions:
How would you approach the design of a social media app or video app?
What are some ways to design a search engine or a ticketing system?
How would you design an API for a payment gateway?
What are some trade-offs and constraints you will consider while designing systems?
What is your rationale for taking a particular approach to problem solving?
Usually, interviewers base the questions depending on the organization, its goals, key competitors and a candidate’s experience level.
For senior roles, the questions tend to focus on assessing the computational thinking, decision making and reasoning ability of a candidate. For entry level job interviews, the questions are designed to test the hard skills required for building a system architecture.
The Difference between a System Design Interview and a Coding Interview
If a coding interview is like a map that takes you from point A to Z – a systems design interview is like a compass which gives you a sense of the right direction.
Here are three key difference between the two:
Coding challenges follow a linear interviewing experience i.e. candidates are given a problem and interaction with recruiters is limited. System design interviews are more lateral and conversational, requiring active participation from interviewers.
Coding interviews or challenges focus on evaluating the technical acumen of a candidate whereas systems design interviews are oriented to assess problem solving and interpersonal skills.
Coding interviews are based on a right/wrong approach with ideal answers to problem statements while a systems design interview focuses on assessing the thought process and the ability to reason from first principles.
How to Conduct an Effective System Design Interview
One common mistake recruiters make is that they approach a system design interview with the expectations and preparation of a typical coding interview. Here is a four step framework technical recruiters can follow to ensure a seamless and productive interview experience:
Step 1: Understand the subject at hand
Develop an understanding of basics of system design and architecture
Familiarize yourself with commonly asked systems design interview questions
Read about system design case studies for popular applications
Structure the questions and problems by increasing magnitude of difficulty
Step 2: Prepare for the interview
Plan the extent of the topics and scope of discussion in advance
Clearly define the evaluation criteria and communicate expectations
Quantify constraints, inputs, boundaries and assumptions
Establish the broader context and a detailed scope of the exercise
Step 3: Stay actively involved
Ask follow-up questions to challenge a solution
Probe candidates to gauge real-time logical reasoning skills
Make it a conversation and take notes of important pointers and outcomes
Guide candidates with hints and suggestions to steer them in the right direction
Step 4: Be a collaborator
Encourage candidates to explore and consider alternative solutions
Work with the candidate to drill the problem into smaller tasks
Provide context and supporting details to help candidates stay on track
Ask follow-up questions to learn about the candidate’s experience
Technical recruiters and hiring managers should aim for providing an environment of positive reinforcement, actionable feedback and encouragement to candidates.
Evaluation Rubric for Candidates
Facilitate Successful System Design Interview Experiences with FaceCode
FaceCode, HackerEarth’s intuitive and secure platform, empowers recruiters to conduct system design interviews in a live coding environment with HD video chat.
FaceCode comes with an interactive diagram board which makes it easier for interviewers to assess the design thinking skills and conduct communication assessments using a built-in library of diagram based questions.
With FaceCode, you can combine your feedback points with AI-powered insights to generate accurate, data-driven assessment reports in a breeze. Plus, you can access interview recordings and transcripts anytime to recall and trace back the interview experience.
Learn how FaceCode can help you conduct system design interviews and boost your hiring efficiency.
Top Products
Explore HackerEarth’s top products for Hiring & Innovation
Discover powerful tools designed to streamline hiring, assess talent efficiently, and run seamless hackathons. Explore HackerEarth’s top products that help businesses innovate and grow.