
So, you have heard of how binary search is used to find the position of an element in a sorted array. That's not the end of the picture. Binary search is a lot more powerful than that. In this article, you will learn some non trivial applications of binary search.
Problem Statement: You are given an array a[1 ... N]. There is some k for which, a[i] = 0 for all i in the range 1 <= i <= k, and a[i] = 1 for all i in the range k + 1 <= i <= N. We want to find this position k which splits the groups of 0s and 1s
Consider this example first:
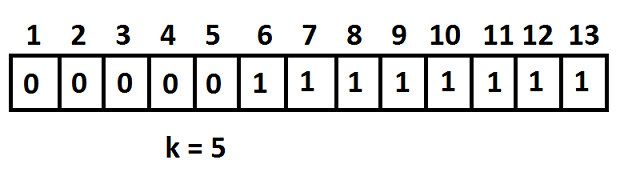
As you can see, we have a[1 .. 5] = 0 and a[6 .. 13] = 1. Our aim is to find the k (here k = 5) at which the split occurs.
A trivial algorithm would be to iterate from right to left and return the value of k at which 0 is seen for the first time. Below is an implementation of this simple algorithm.
#include <bits/stdc++.h>
using namespace std ;
int main() {
int n, k ;
scanf("%d", &n) ;
vector <int> a(n + 1) ;
for(int i = 1 ; i <= n ; i++)
scanf("%d", &a[i]) ;//make sure that the first few elements are 0 and the next few are 1
for(k = n ; k >= 1 ; k--) {
if(a[k] == 0) {
printf("%d\n", k) ;
break ;
}
}
if(k == 0)
printf("Array is all 1s\n") ;
}Clearly this naive approach has a worst case time complexity of O(N), where N is the size of the array. Can we do better? Yes we can! This is where binary search comes to our rescue!
So what is the approach? Well, firstly observe that the array is sorted (0s appear and then 1s appear). And our task is to find some element. So, this clearly hints that its a binary search problem.
Here is the idea:
- set lo = 1 and hi = N (where N is the size of the array)
- set mid = (hi + lo + 1) / 2
- if a[mid] is 1, then our k lies in the part a[lo .. mid - 1]
- if a[mid] is 0, then our k lies in the part a[mid .. hi]
- solve recursively until lo and hi converge
Here is an implementation
#include <bits/stdc++.h>
using namespace std ;
void findk(vector <int>& a) {
int lo = 1, hi = a.size() - 1, mid ;
while(lo < hi) {
mid = (lo + hi + 1) / 2 ;
if(a[mid] == 0)
lo = mid ;
else
hi = mid - 1 ;
}
if(a[lo] == 0)
printf("%d\n", lo) ;
else
printf("Array is all 1s\n") ;
}
int main() {
int n ;
scanf("%d", &n) ;
vector <int> a(n + 1) ;
for(int i = 1 ; i <= n ; i++)
scanf("%d", &a[i]) ; //make sure that the first few elements are 0 and the next few are 1
//note that we discard a[0] because we are considering a[1 .. n]
findk(a) ;
}The idea is essentially the idea of "search space". The 2 pointers lo and hi define our search space. That is, our search space is a[lo .. hi].
It is clear that if a[mid] is 1, then k lies in the part a[lo .. mid - 1] and so, we set hi = mid - 1 to appropriately change our search space.
Also, if a[mid] = 0, then 2 cases arise:
- the k we are looking for is same as mid
- the k we are looking for is greater than mid
The value of k cannot be less than mid because we are searching for the last zero from the left and so, our search space now consists of the interval a[mid .. hi].
Now why did we choose mid = (hi + lo + 1) / 2 and not (hi + lo) / 2 - we will discuss this later.
Lets focus first on the analysis of this algorithm.
In each step, this algorithm halves the array and so, we can say that T(N) = T(N / 2) + c, which on solving gives T(N) = O(logN) and this is much faster than our naive approach.
Coming back to the question, why did we choose mid = (hi + lo + 1) / 2 and not (hi + lo) / 2. Well, this one is tricky, but I will try to convince you why its important to add that 1 factor.
Consider an array of size 2 where a1 = 0 and a[2] = 1. Clearly, the answer is k = 1 for this array.
While running the algorithm, we set lo = 1, hi = 2
In this case, our algorithm essentially "rejects" a part of search space in every iteration. Our search space here is [1, 2] and we want to reject the portion [2 .. 2] and so, when we evaluate mid = (hi + lo + 1) / 2, we get that mid = 2. We then compare a[2] with 1 and then we set hi = mid - 1 = 1, rejecting the [2 .. 2] part.
Try this yourself to realize it better. Just write mid = (hi + lo) / 2 instead of (hi + lo + 1) / 2 and you will see that the algorithm gets stuck indefinitely.
Now how is this useful?
Well, yes we barely get a problem as mentioned above. However, you may see such a problem in disguise. How? Read on
Let us say that we are given a function f(x), which is decreasing up to a certain value and is increasing later on. We are also given a function isIncreasing(val), which evaluates to true if f(val) is increasing and it evaluates to false if f(val) is decreasing.
We aim to find the last value up to which f(x) is decreasing.
Additionally we are given an interval of [0 .. n] for the domain of f(x).
We can easily apply the above discussed concept here.
Let the value desired be k. Clearly, f(x) is decreasing for 0 <= x <= k and f(x) is increasing for k + 1 <= x <= n and so, this is exactly the problem above!
How? Observe that if you create an array a[0 .. n], where a[i] = 0 if isIncreasing(i) = false and a[i] = 1 if isIncreasing(i) = true, then you will get the array as desired. But, here we don't have to create the array.
What we can do is simply set lo = 0, hi = n and evaluate isIncreasing(mid). It it returns true, we set lo = mid, else we set hi = mid - 1. So, we do not really have to create the array here.
Instead of doing a linear search, we can apply the above idea to this problem to do a binary search and be done in just O(logn) time!
I hope you learnt something new from this article :)
Author
Trending Notes
Python Diaries Chapter 3 Map | Filter | For-else | List Comprehension
written by Divyanshu Bansal
Bokeh | Interactive Visualization Library | Use Graph with Django Template
written by Prateek Kumar
Bokeh | Interactive Visualization Library | Graph Plotting
written by Prateek Kumar
Python Diaries chapter 2
written by Divyanshu Bansal
Python Diaries chapter 1
more ...
written by Divyanshu Bansal
{"1c781a5": "/users/pagelets/trending_card/?sensual=True"}