
INTRODUCTION A* is the most popular choice for pathfinding, because it’s fairly flexible and can be used in a wide range of contexts. A* is like other graph-searching algorithms in that it can potentially search a huge area of the map. It’s like Dijkstra’s algorithm in that it can be used to find a shortest path. It’s like Greedy Best-First-Search in that it can use a heuristic to guide itself. In the simple case, it is as fast as Best-First-Search:
Below is an image showing you how Djikstra's algorithm works. The blue color shows the number of nodes visited by Djikstra's algorithm

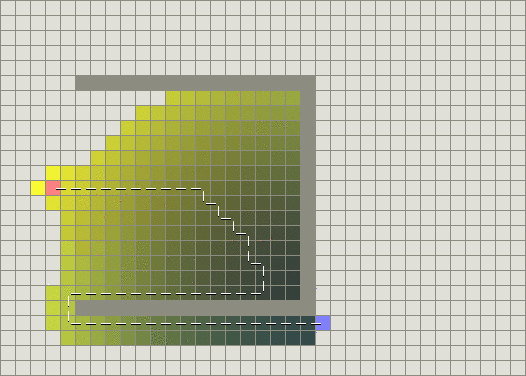
Below is an image showing you how Best First search algorithm works. The colored nodes show the number of nodes visited. Yellow color means nodes closer to source node and green means nodes closer to the destination

Now, Djikstra's algorithm is guaranteed to always give you the best path. As it uses 'exact cost' needed to visit from one node to the other. But Best First Search is not guaranteed to always give you the best path. This is because it uses a function 'heuristic' which is an estimate distance from one node to the destination. So Best First Search will not give you the correct shortest path when there is an obstacle as shown in the image below.
But Djikstra's algorithm, as I said, is guaranteed to give you the correct path and hence it will give you the correct path as shown below

This leads to the importance of A* search algorithm, which is a combination of Djikstra's and Best First Search algorithms. It uses the sum of 'cost' (distance from source to the current node, defined by g(x)) as well as 'heuristic' (estimated distance from current node to destination, defined by h(x)).
So the A* will give you the correct results even if there is an obstacle PROVIDED, the estimated values,i.e., the heuristics is consistent. I will get back to what is consistency in heuristics. This video will explain this better (http://www.youtube.com/watch?v=DhtSZhakyOo). i recommend people who want more clarity with examples at this point to go through this video.
IMPLEMENTATION : So, basically instead of checking for g(x) for the current node like in Djisktra's we check for f(x) = g(x) + h(x) for the current node in A search algorithm. g(x) is the distance from source to parent + distance from parent to the current node. h(x) is a function which is already computed for each of the nodes and hence this value is directly used. Now in A we do not visit all the nodes. So, we start from the source node, and then extract all the neighbors, then for each neighbor add its g value (distance from parent to this neighbor) to the g value of the parent, then add its h value to this, giving you the f value (f = g + h). Then add this all these neighbors to a priority queue with f values. These nodes are now OPEN to calculate and the source node is CLOSED to calculate. (Initially the source node is OPEN and CLOSED list is empty). Now we go to the node with the shortest f value (if the destination is not already reached) and then extract it only if this node does not already has a shorter path available (shorter f value, which is maintained in a list for each node, which is initially infinity for all). If there is already a shorter node to a current node, this means that this particular path is not the shortest and hence we do not expand its neighbors and we can make this node as CLOSED and return to the next shortest path in the priority queue. This is now repeated till we reach our destination. the moment we reach the destination it is the shortest path, and a guaranteed one if the heuristic is consistent.
HEURISTIC Now, a question which will be running in your mind is how to calculate h(x). We have Manhattan method which is the most popular one. It finds the approx distance between a current node and the destination by a function. So, for calculating, we need to understand why it fails to find the shortest path when it is not consistent. I recommned you to get a pen and paper for this. A S C G B
Assume this is a graph. Edges are SA, SB, AB, AC, BC, AG, CG. g values are SA = 1, SB = 4, AB = 2, BC = 2, AC = 5, CG = 3, AG = 12. Let h values are S=7, A=6, B=2, C=1, G=0.
Now, state of A & B are the same (same parent). If your heuristics are not consistent, there are chances that you will miss a shortest path because you marked a node as CLOSED and its shortest path is reached after it is CLOSED. By closed I mean removing it from the priority queue (Remember that you close the node as soon as you evaluate it in the priority queue).
What you will do is, in priority queue, you will have f values for each step as 1. S = 7 (0+7), 2. SA = 7 (0+1+6) , SB = 6 (0+4+2) 3. Now in priority queue you will evaluate SB first. and then you will mark B as CLOSED. And when you reach SAB, you will not evaluate this path as B is already CLOSED.
hence you will get SACG as the shortest path (cost = 9). But the shortest path is SABCG(cost=8). This is because heuristic is not consistent.
The only condition for h(x) to be consistent is that - for all the nodes, the difference of h values between them should be lower then the distance between their g values. In this example, the difference between g values of A and B was 2 and h values was 4, and hence heuristic was not consistent. Hence if you repeat this problem with Heuristic function as (S=7, A=6, B=4, C=2, G=0) then your shortes path will be guaranteed to be correct through A* algorithm.
If you have not already gone through the above mentioned video, I would highly recommend you to go through it.
Hence, One way to construct an exact heuristic is to precompute the length of the shortest path between every pair of points. This is not feasible for most graphs. However, there are ways to approximate this heuristic, and this gets very tricky :
Fit a coarse grid on top of the fine grid. Precompute the shortest path between any pair of coarse grid locations. Precompute the shortest path between any pair of waypoints. This is a generalization of the coarse grid approach. Then add in a heuristic h' that estimates the cost of going from any location to nearby waypoints. (The latter too can be precomputed if desired.) The final heuristic will be:
h(n) = h'(n, w1) + distance(w1, w2) + h'(w2, goal)
or if you want a better but more expensive heuristic, evaluate the above with all pairs w1, w2 that are close to the node and the goal, respectively.
APPLICATION OF A* Algorithm Used in calculating shortest paths for movement of characters in games, hence Game Programming industry is the biggest industry to use this algorithm. As this is successful with obstacles as well.
/**
* A* algorithm implementation using the method design pattern.
*
*/
import java.util.*;
public abstract class AStar<T>{
private class Path implements Comparable{
public T point;
public Double f;
public Double g;
public Path parent;
/**
* Default c'tor.
*/
public Path(){
parent = null;
point = null;
g = f = 0.0;
}
/**
* C'tor by copy another object.
*
* @param p The path object to clone.
*/
public Path(Path p){
this();
parent = p;
g = p.g;
f = p.f;
}
/**
* Compare to another object using the total cost f.
*
* @param o The object to compare to.
* @see Comparable#compareTo()
* @return <code>less than 0</code> This object is smaller
* than <code>0</code>;
* <code>0</code> Object are the same.
* <code>bigger than 0</code> This object is bigger
* than o.
*/
public int compareTo(Object o){
Path p = (Path)o;
return (int)(f - p.f);
}
/**
* Get the last point on the path.
*
* @return The last point visited by the path.
*/
public T getPoint(){
return point;
}
/**
* Set the
*/
public void setPoint(T p){
point = p;
}
}
/**
* Check if the current node is a goal for the problem.
*
* @param node The node to check.
* @return <code>true</code> if it is a goal, <code>false</else> otherwise.
*/
protected abstract boolean isGoal(T node);
/**
* Cost for the operation to go to <code>to</code> from
* <code>from</from>.
*
* @param from The node we are leaving.
* @param to The node we are reaching.
* @return The cost of the operation.
*/
protected abstract Double g(T from, T to);
/**
* Estimated cost to reach a goal node.
* An admissible heuristic never gives a cost bigger than the real
* one.
* <code>from</from>.
*
* @param from The node we are leaving.
* @param to The node we are reaching.
* @return The estimated cost to reach an object.
*/
protected abstract Double h(T from, T to);
/**
* Generate the successors for a given node.
*
* @param node The node we want to expand.
* @return A list of possible next steps.
*/
protected abstract List<T> generateSuccessors(T node);
private PriorityQueue<Path> paths;
private HashMap<T, Double> mindists;
private Double lastCost;
private int expandedCounter;
/**
* Check how many times a node was expanded.
*
* @return A counter of how many times a node was expanded.
*/
public int getExpandedCounter(){
return expandedCounter;
}
/**
* Default c'tor.
*/
public AStar(){
paths = new PriorityQueue<Path>();
mindists = new HashMap<T, Double>();
expandedCounter = 0;
lastCost = 0.0;
}
/**
* Total cost function to reach the node <code>to</code> from
* <code>from</code>.
*
* The total cost is defined as: f(x) = g(x) + h(x).
* @param from The node we are leaving.
* @param to The node we are reaching.
* @return The total cost.
*/
protected Double f(Path p, T from, T to){
Double g = g(from, to) + ((p.parent != null) ? p.parent.g : 0.0);
Double h = h(from, to);
p.g = g;
p.f = g + h;
return p.f;
}
/**
* Expand a path.
*
* @param path The path to expand.
*/
private void expand(Path path){
T p = path.getPoint();
Double min = mindists.get(path.getPoint());
/*
* If a better path passing for this point already exists then
* don't expand it.
*/
if(min == null || min.doubleValue() > path.f.doubleValue())
mindists.put(path.getPoint(), path.f);
else
return;
List<T> successors = generateSuccessors(p);
for(T t : successors){
Path newPath = new Path(path);
newPath.setPoint(t);
f(newPath, path.getPoint(), t);
paths.offer(newPath);
}
expandedCounter++;
}
/**
* Get the cost to reach the last node in the path.
*
* @return The cost for the found path.
*/
public Double getCost(){
return lastCost;
}
/**
* Find the shortest path to a goal starting from
* <code>start</code>.
*
* @param start The initial node.
* @return A list of nodes from the initial point to a goal,
* <code>null</code> if a path doesn't exist.
*/
public List<T> compute(T start){
try{
Path root = new Path();
root.setPoint(start);
/* Needed if the initial point has a cost. */
f(root, start, start);
expand(root);
for(;;){
Path p = paths.poll();
if(p == null){
lastCost = Double.MAX_VALUE;
return null;
}
T last = p.getPoint();
lastCost = p.g;
if(isGoal(last)){
LinkedList<T> retPath = new LinkedList<T>();
for(Path i = p; i != null; i = i.parent){
retPath.addFirst(i.getPoint());
}
return retPath;
}
expand(p);
}
}
catch(Exception e){
e.printStackTrace();
}
return null;
}
}
Author
{"5bdcf10": "/users/pagelets/trending_card/?sensual=True"}