
Introduction
Machine Learning Challenge #1 was held from March 16 - March 27 2017. More than 3000 machine learning enthusiasts across the world registered for the competition. The competition saw participants fighting hard for the top spot.
Some of them gave up just before the finishing line, but the rest persisted by training, re-training, tuning their models. More than machine learning, the data set shared in this challenge gave participants enough opportunity to practice data cleaning and feature engineering in detail. In fact, the top 4 participants banked heavily on feature engineering to achieve their scores. The key to feature engineering is simple: think logically and don't judge whatever new features you are thinking of. Try every feature in your model. Who knows which one turns out to be the golden feature? The difference between being a participant and being a winner is that winners try every possible way to reach their goal but participants lose time deciding which way would work.
Here's your chance to learn from winners and practice machine learning in new ways. If you need to know anything more about a solution, feel free to drop your question in Comments below.
Rank 4 - Bhupinder Singh
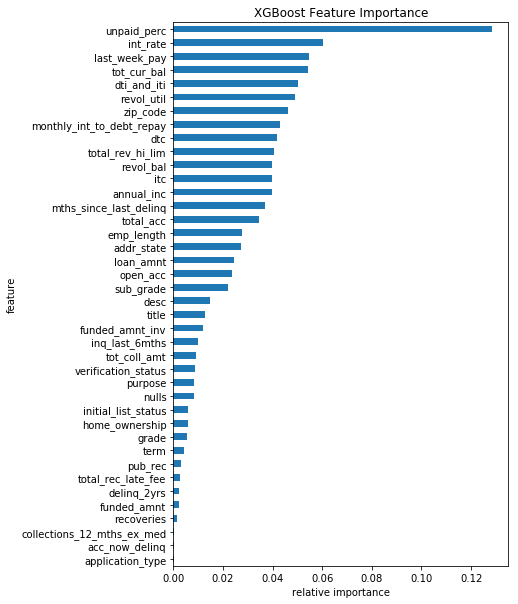
Bhupinder is a web developer in Photon, Chennai, India. He scored 0.97927 on private LB. He used XGBoost in python. Some of the key insights are
- Created a feature 'unpaid percentage of interest' by [(interest - paid interest)/interest]. For approximating interest, he used the simple interest formula (p * r * t)/100. This new feature alone, along with raw features gave 0.976 AUC on public LB. It turned out to be the most important of all.
- Final solution was derived from ensembling 5 XGBoost models.
Code link: Click Here
[Rank 3 - Yuvraj Rathore] (https://www.hackerearth.com/@yuvraj35)
Yuvraj Rathore is a student at IIT Madras. In conversation with us, he shared the following approach:
1. Data Pre-processing
- I didn't do too much data pre-processing except missing value treatment. Missing values for revolving credit limit was filled using the product of revol_bal and revol_util.
- For other missing values, I used -1. This was done to give them a level of their own.
2. Feature Engineering
- I made a lot of features, but two features stood out in terms of performance:
- Ratio of insurance paid by the customer to total insurance due.
- Using batch_enrolled as a feature. Most of the batches contained some unique no of last_week_pay in them. But batch numbers are different in test and train. To overcome that, I used counts of a particular last week pay for a particular patch/ total counts of that batch as a feature.
-
Using the above two features plus the given numerical features in the data set, I could achieve a score of around 97 on the LB. Some other custom features that gave me a limited increase in the score were:
- total_loan
- A Boolean feature saying whether the loan applied by the customer and that sanctioned by the investors are the same.
- loan left to pay
- ratio of applied loan to annual income
- ratio of balance in account to revolving credit
-
I didn't use any of the text features such as desc, purpose, etc. Moreover, I didn't pick up the leak in member_id.
3. Model Training
- My choice of model was empirical in nature. XGB gave me the highest score on CV set. My final submission was an average of 5 XGB scripts. The five models were trained on different chunks of the training data using stratified K-fold CV. Due to paucity of time, I couldn't ensemble
Code Link: Click Here
Rank 1 - Evgeny Patheka
Evgeny Patheka is an economist, and an expert in budgeting and accounting, from Moscow, Russia. His solutions are implemented in several top Russian companies. In conversation with us, he said:
This is what he had to say about this challenge:
"It was a really interesting feature engineering competition for me. Thanks to the organizers and all participants! I used R with data.table, XGBoost, and LightGBM libraries. LightGBM is very similar to XGBoost, much faster but has a little bit less accuracy. It very useful to test some ideas by fast LightGBM and run XGBoost after you choose a good set of features.
I think the main success factor for me - good validation scheme. I used 5-folds cross-validation with data split up between folds by batch_enrolled. I found that test and train sets have no batches in common. Different batches have very different default probability and if you split up train data between folds as stratified by result label only, your validation set had leak by batches which could significantly distort results.
It was much better to split up data between folds by batches. I didn't find a good machine solution to split up data with equal amounts of positive loan_status in each fold and did it by hand.
It was very useful - after I did that, my cross-validation results became very similar to the public leaderboard scores and I could test different ideas with high accuracy without overfitting. I used most of existing features except job and purpose descriptions and some features with very little information.
I also used member_id as a feature, because it contains very important info (small IDs older and have higher probability of default than big IDs). I think it was a little mistake on the organizer\u2019s side to keep original member ID; it would be better to create random ID instead. But it was not fatal trouble for our competition. I created a lot of features and found some gems.
Most important:
dt[, total_rec_int_to_funded:=total_rec_int/(funded_amnt*int_rate)]
dt[, total_rec_int_to_funded_to_term:=total_rec_int_to_funded/term]
dt[, total_rec_int_to_funded_by_sgrade:=(total_rec_int_to_funded-mean(total_rec_int_to_funded))/sd(total_rec_int_to_funded), by=.(sub_grade)]
dt[, last_week_pay_by_batch:=(last_week_pay-mean(last_week_pay))/sd(last_week_pay), by=.(batch_enrolled)]
dt[, last_week_pay_by_id300k:=(last_week_pay-mean(last_week_pay))/sd(last_week_pay), by=.(ceiling(member_id/300000)*300000)]
Code Link: Click Here
Note: Divanshu Garg, Rank 2 refused to share his approach and source code since he used some proprietary tool for analysis. Hence, the second prize ($200) got passed to Rank 3 participant (Yuvraj Rathore).
Key Learnings from ML Challenge #1
- Even before you think of which algorithm to use, think about what the data has to say. Try to explore data from all possible angles.
- Never underestimate any feature. Even high cardinality variables like IDs sometimes carry a hidden pattern.
- Always try creating new features. Sometimes, one new feature can put you in the top 10 on the leaderboard.
- You must learn XGBoost tuning.(Hands-on is more important.)